AQUA
AQUA 是 Redshift 的Advanced Query Accelerator(高级查询加速器)的缩写。这是 AWS 在 2020 年推出的一项创新技术,专门用于加速 Redshift 数据仓库的查询性能。
它是 Redshift 的硬件加速缓存层,把部分查询计算下推到存储层执行,减少数据移动,提升扫描密集型查询性能最高 10 倍。
传统架构(无 AQUA):
┌─────────────────┐
│ Compute Nodes │ ← 所有计算在这里
│ (RA3 节点) │
└────────┬────────┘
│ 拉取大量数据
▼
┌─────────────────┐
│ Managed Storage│ ← 只存数据
│ (S3) │
└─────────────────┘
有 AQUA 架构:
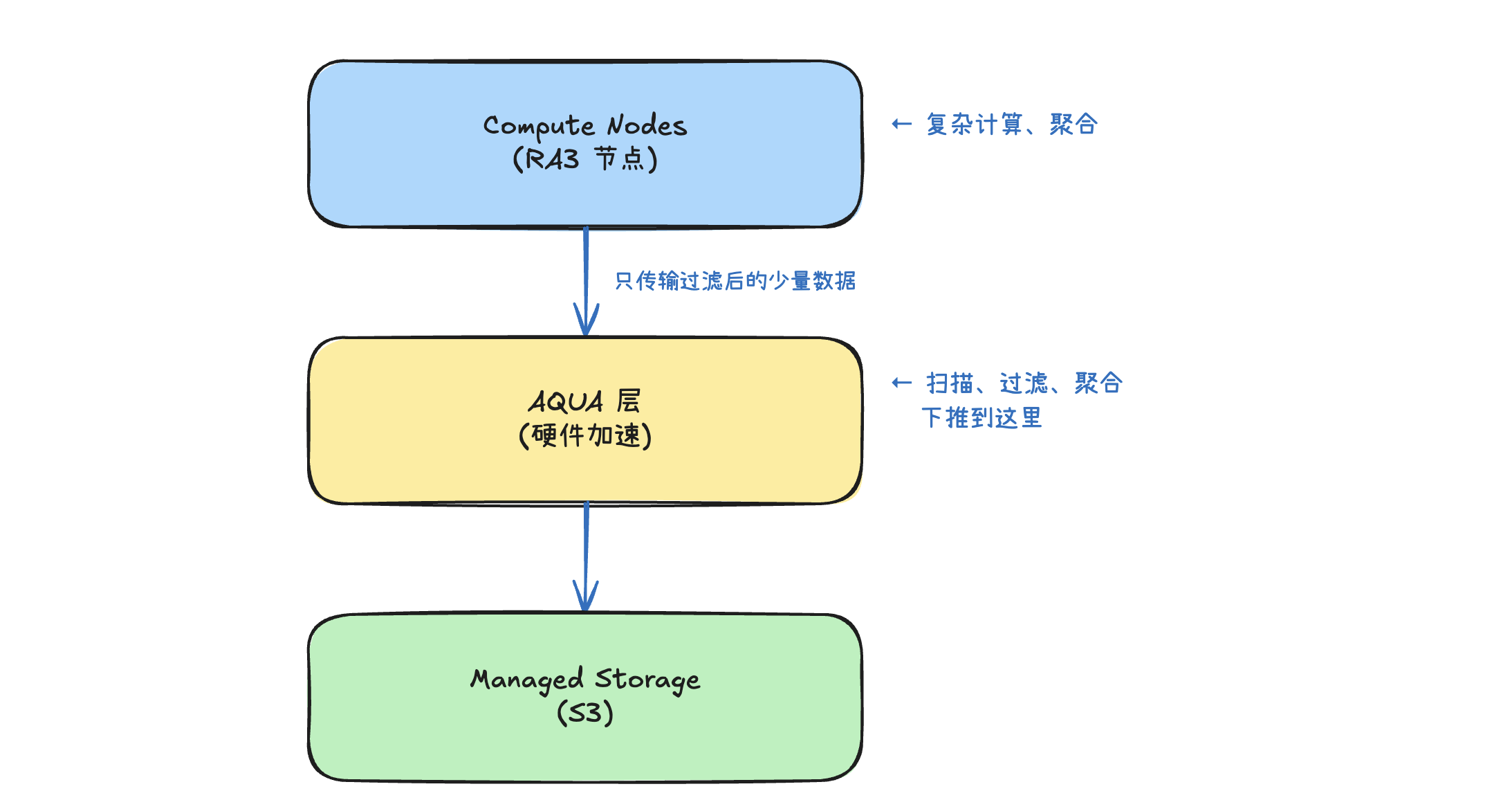
核心原理
| 概念 | 说明 |
|---|---|
| 计算下推 | 把 SCAN、FILTER、部分聚合推到存储层执行 |
| 硬件加速 | 使用 AWS 自研芯片(Nitro + FPGA)加速 |
| 减少数据移动 | 只把过滤后的结果发给 Compute Node |
| 自动启用 | 无需配置,Redshift 自动决定是否使用 |
哪些操作会被加速
| 操作类型 | 是否下推 AQUA |
|---|---|
| 全表扫描 | ✅ |
| WHERE 过滤 | ✅ |
| LIKE 模糊匹配 | ✅ |
| 聚合(SUM/COUNT/AVG) | ✅ 部分 |
| JOIN | ❌ 在 Compute Node |
| 复杂函数 | ❌ 在 Compute Node |
这类查询受益最大(大表扫描 + 过滤):
SELECT COUNT(*)
FROM huge_table
WHERE event_date = '2024-02-24'
AND status = 'active';
-- 无 AQUA:扫描 100GB → 传输 100GB → Compute 过滤
-- 有 AQUA:扫描 100GB → AQUA 过滤 → 传输 1GB → Compute 聚合
支持的节点类型
| 节点类型 | AQUA 支持 |
|---|---|
| RA3.xlplus | ✅ |
| RA3.4xlarge | ✅ |
| RA3.16xlarge | ✅ |
| DC2 系列 | ❌ |
| DS2 系列 | ❌ |
只有 RA3 节点支持 AQUA
查看 AQUA 状态
-- 查看 AQUA 状态
SELECT * FROM svv_aqua_configuration;
-- AQUA 是自动启用的,无需手动配置
-- 可以在集群级别调整
-- Console → Cluster → Modify → AQUA Configuration
有以下三个配置
| 设置 | 说明 |
|---|---|
| Auto | Redshift 自动决定(默认) |
| Enabled | 强制启用 |
| Disabled | 禁用 |
查看 AQUA 是否被使用:
-- 查询执行计划
EXPLAIN SELECT * FROM large_table WHERE id = 123; -- 输出中可能看到 "AQUA Scan" 字样
-- 查看执行统计
SELECT
query,
segment,
step,
label,
is_diskbased,
workmem,
bytes
FROM svl_query_summary
WHERE query = <query_id>;
-- 系统视图查看 AQUA 统计
SELECT * FROM svcs_aqua_scanned;
费用
| 项目 | 费用 |
|---|---|
| AQUA | ✅ 免费 |
AQUA 包含在 RA3 节点价格中,不额外收费。
与其他加速技术对比:
| 技术 | 加速方式 | 适用场景 |
|---|---|---|
| AQUA | 存储层硬件加速 | 大表扫描、过滤 |
| Result Cache | 缓存查询结果 | 重复查询 |
| Compiled Code Cache | 缓存执行计划 | 重复 SQL 模式 |
| Concurrency Scaling | 增加计算资源 | 高并发 |
| Materialized Views | 预计算存储 | 复杂聚合 |
最佳实践
| 建议 | 说明 |
|---|---|
| 使用 RA3 节点 | 只有 RA3 支持 AQUA |
| 保持 Auto 模式 | Redshift 自动优化 |
| 大表受益大 | GB/TB 级表扫描性能提升明显 |
| 监控使用情况 | 通过系统视图分析 |