Redshift Spectrum
假设我们想对很大的数据集时做查询,此时需要把数据加载到Redshift,加载完成后,我们也不知道后面会不会再查它:
- 如果删掉Redshift,下次查询时还要创建集群并导入数据,比较花时间
- 如果不删除,数据量很大会占用Redshift磁盘空间,造成浪费
数据保存到S3的价格远远低于Redshift磁盘的费用,Redshift Spectrum就是利用这个优势,直接从S3上查询数据,处理完成后把结果和Redshift存储的数据做join查询。这样一来我们只需要把经常查询用到的数据放在Redshift
在执行Spectrum查询时,worker节点会检查Data Catalog,以找到S3上数据的位置:

Redshift Spectrum底层是上千台自动伸缩的EC2。
总结来说:
传统方式:
S3 数据 → COPY 导入 → Redshift 表 → 查询
Spectrum 方式:
S3 数据 → 直接查询(不导入)
Redshift Spectrum和S3的对比
RA3 集群(托管存储):
┌─────────────────┐
│ Redshift │
│ Compute Node │
└────────┬────────┘
│
┌────────▼────────┐
│ Managed Storage│ ← AWS 托管的 S3(用户不可见)
│ (RMS) │ 数据格式:Redshift 内部格式
└─────────────────┘
Spectrum(外部表):
┌─────────────────┐
│ Redshift │
│ Compute Node │
└────────┬────────┘
│
┌────────▼────────┐
│ Spectrum 层 │ ← AWS 托管的计算节点池(按需)
└────────┬────────┘
│
┌────────▼────────┐
│ 你的 S3 桶 │ ← 用户自己的 S3(用户可见、可控)
│ (Parquet/CSV等) │ 数据格式:开放格式
└─────────────────┘
核心区别:
| 特性 | RA3 (Managed Storage) | Spectrum (外部表) |
|---|---|---|
| 数据位置 | AWS 托管 S3(不可见) | 你自己的 S3(可见可控) |
| 数据格式 | Redshift 内部格式 | Parquet/ORC/CSV/JSON 等 |
| 需要导入 | ✅ COPY 导入 | ❌ 直接查外部 |
| 查询性能 | ⚡ 最快 | 🐢 较慢 |
| 数据可共享 | Redshift 集群间 | 任何系统(Athena/EMR等) |
| 存储费用 | RMS: $0.024/GB/月 | S3: $0.023/GB/月 |
| 计算费用 | 包含在节点费用 | 扫描费: $5/TB |
我们将从以下几个维度来分析费用:
spectrum多了扫描费
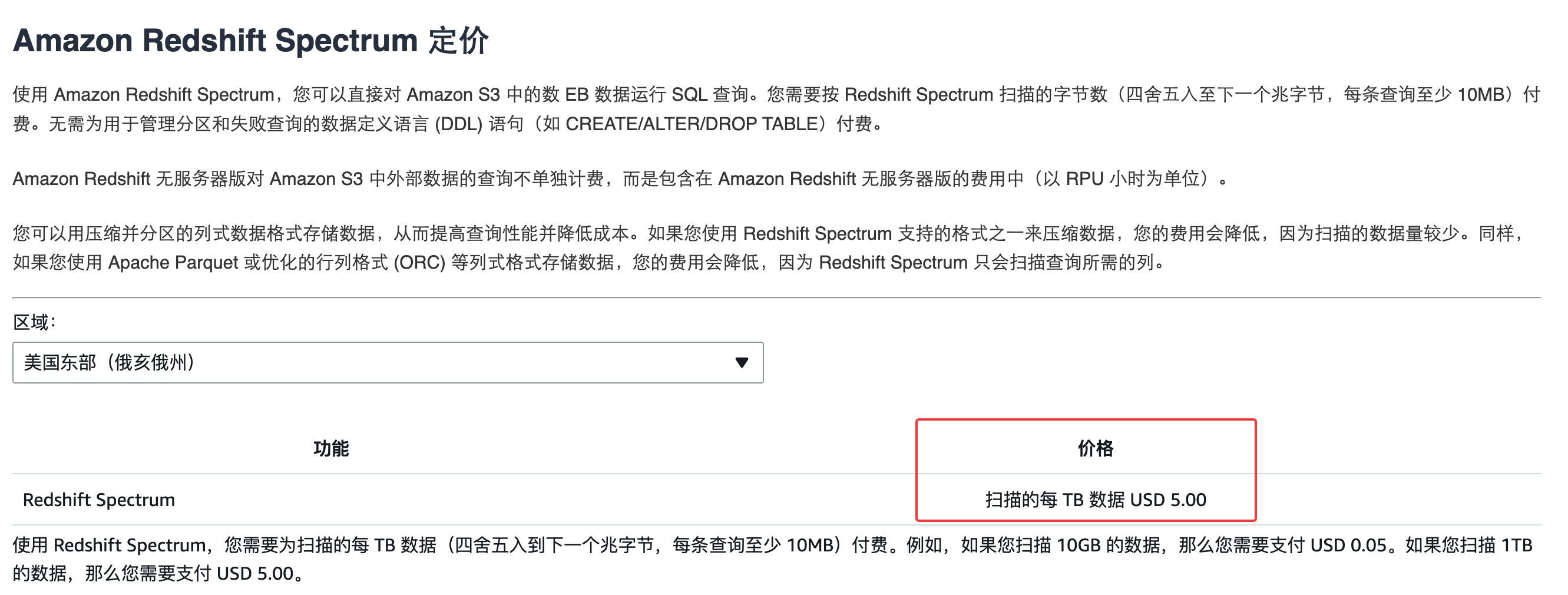
| 方式 | 费用模式 |
|---|---|
| RA3 查本地表 | 无额外费用(已含在节点费) |
| Spectrum 查 S3 | $5/TB 扫描量 |
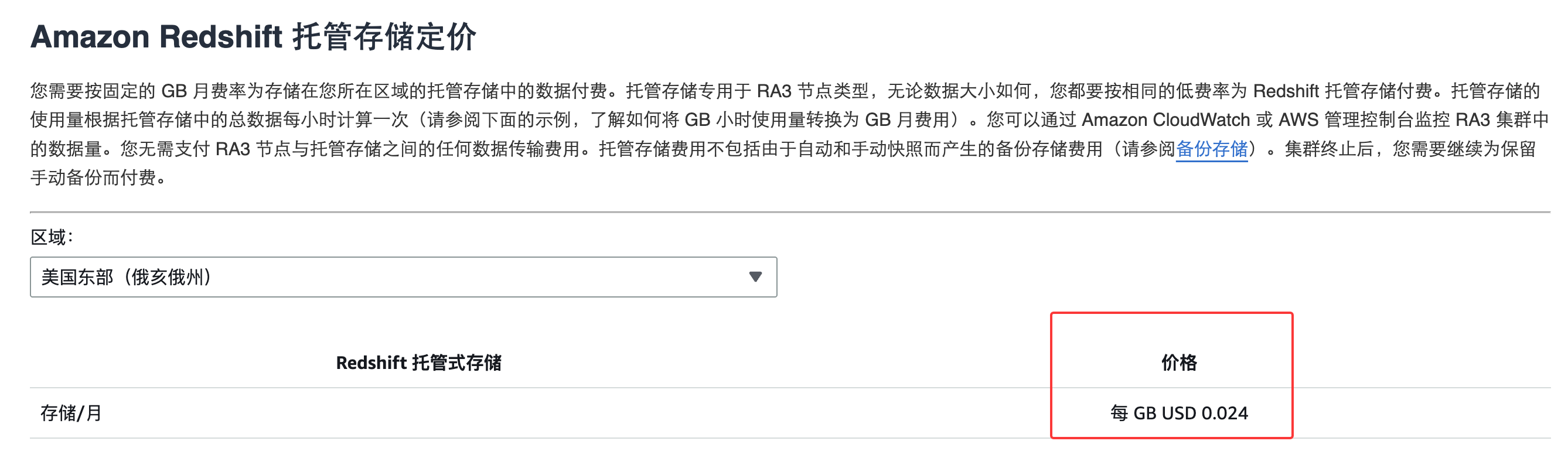
存储
ra3的是每GB 0.024:
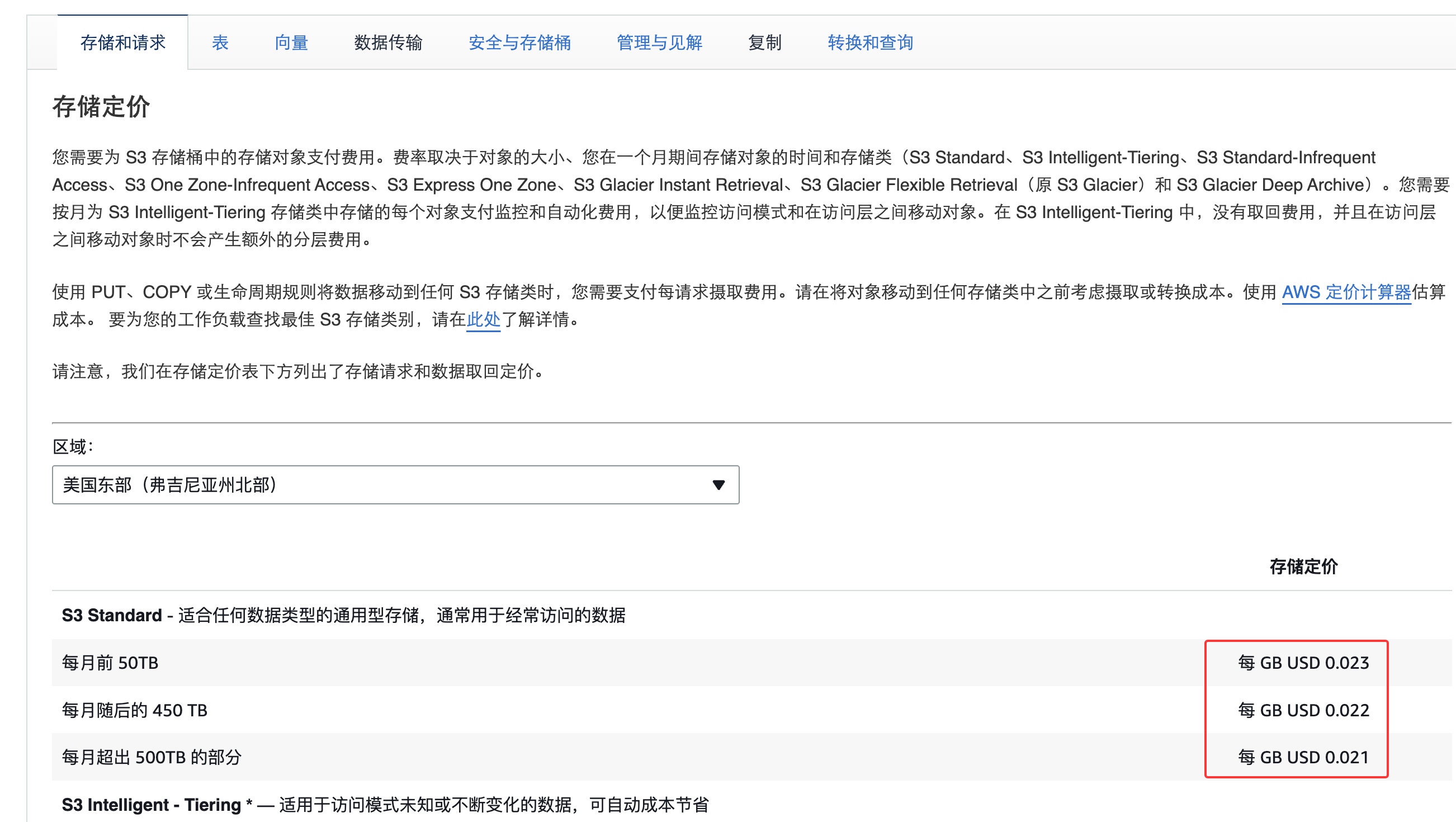
S3是每GB 0.023:
所以,什么时候用 Spectrum要考虑场景:
| 场景 | 推荐 |
|---|---|
| 数据已在 S3,偶尔分析 | ✅ Spectrum |
| 历史归档数据,低频查询 | ✅ Spectrum |
| 与其他系统共享数据(Athena/EMR) | ✅ Spectrum |
| 高频查询、性能要求高 | ❌ 用 RA3 本地表 |
| 数据量小(<1TB) | ❌ 直接导入 RA3 |
Spectrum 创建外部表示例:
-- 1. 创建外部 Schema(指向 Glue Catalog)
CREATE EXTERNAL SCHEMA spectrum_schema
FROM DATA CATALOG
DATABASE 'my_glue_db'
IAM_ROLE 'arn:aws:iam::123456789:role/RedshiftSpectrumRole';
-- 2. 查询 S3 数据(就像普通表)
SELECT * FROM spectrum_schema.logs
WHERE log_date = '2024-01-01';
-- 3. 混合查询(本地表 JOIN 外部表)
SELECT o.*, l.*
FROM local_orders o
JOIN spectrum_schema.logs l ON o.id = l.order_id;
总结
| 问题 | 答案 |
|---|---|
| Spectrum 底层是 S3 吗? | ✅ 是,你自己的 S3 桶 |
| 存储谁便宜? | 几乎一样,S3 略便宜 |
| 查询谁便宜? | RA3 本地表(无额外费),Spectrum 按扫描量收费 |
| 性能谁好? | RA3 本地表更快 |
| 什么时候用 Spectrum? | 冷数据、低频查询、数据共享场景 |